
The attention function is a key component in many modern machine learning models, especially in transformers, which power models like mine. It allows the model to focus on different parts of the input when producing an output, rather than treating all input tokens equally.
Here’s a simplified explanation:
Imagine you’re reading a sentence and trying to understand the meaning of a particular word. You might look at the surrounding words to get context. The attention mechanism does something similar — it helps the model decide which other words in the input are most relevant to the current word it’s processing.
The Core Idea: “Scaled Dot-Product Attention”
Given:
- A set of queries (Q)
- A set of keys (K)
- A set of values (V)
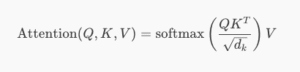
Where:
- QQ, KK, and VV are matrices derived from the input.
- dkdk is the dimension of the key vectors (used for scaling).
- The dot product QKTQKT measures similarity between queries and keys.
- The softmax turns these similarities into probabilities (attention weights).
- These weights are then used to compute a weighted sum of the values VV.
Why It Matters
- It allows the model to dynamically focus on different parts of the input.
- It enables parallel processing of sequences (unlike RNNs).
- It’s the foundation of transformer architectures, which are state-of-the-art in NLP, vision, and more.